Activity › Forums › Astrotechniek › Methoden en Technieken › Meten van field curvature (beeldveldwelving) en tilt (kanteling)
- This topic has 27 replies, 3 voices, and was last updated 4 years, 2 months ago by
 han.k.
han.k.
-
AuthorPosts
-
January 27, 2020 at 20:26 #22930
 InFINNityDeckParticipant
InFINNityDeckParticipantHoi Han,
ik zat me vanochtend precies hetzelfde af te vragen (of dit draadje niet wat te technisch is). Maar laten we het van de positieve kant bekijken: gezien het weer zou het anders nu wel erg stil zijn op het forum… :-) Misschien moet er naast de comment en like knoppen een [TE TECHNISCH]-knopje komen? ;-)
Ik begrijp wat je bedoelt en het is iets dat bij een tweede-orde fit niet gebeurt, daar werkt MAD uitstekend. Tijdens de ontwikkelfase zijn er honderden focus-curves door de routines getrokken en een eenzijdige verwerping is daar niet gebeurd. Wat dat betreft is die tweede-orde fit per ongeluk een gelukkige goede keuze geweest.
Als ik nog wat slims bedenk, meld ik me weer.
Nicolàs
https://www.dehilster.info/astronomy
In the observatory: Mount: 10Micron GM3000HPS, OTAs mounted: SW Esprit 80ED & Esprit 150ED, Celestron C11 XLT EdgeHD, Lunt LS80THA single stack, GTT60 (60mm aperture Galilean Type Telescope), Cameras: ZWO ASI1600MM Cool (2x), ASI174MM, ASI290MM & MC, QHYCCD QHY163M, OTAs on the ground: SW Explorer 300PDS, Bresser Messier 130/650 & 90/500.
January 27, 2020 at 21:31 #22934 BakxParticipant
BakxParticipantHet staat een ieder vrij om een draadje al dan niet te lezen. Toch?
Persoonlijk vind ik dit wel interessant.
Het geeft de leek toch wat inzicht in de complexiteit van ogenschijnlijk triviale zaken.
January 28, 2020 at 14:07 #22953 han.kParticipant
han.kParticipantEen laatste post in deze lange draad.
Ook het idee om focus V-curve fit outliers te verwijderen met de standaard statistics heb ik verlaten. Ik merkte dat de routine altijd minstens een outlier vond door de vreemde populatie (geen standaard verdeling) van de fouten. De routine was altijd bruikbare data aan het weggooien. De grootste afwijking zijn niet altijd een outlier.
Nietemin heeft dit experiment toch was goeds opgeleverd. De fout van de curve-fit bepaal ik nu als de gemiddelde fout en niet langer als het kwadratisch gemiddelde (RMS). De invloed van grote outliers is hierdoor minder (geen kwadraat). Verder details en nieuwe screenshots zijn te vinden op de bug report page van CCDCiel, want daarin wordt het ook verwerkt. :) Commentaar kan ook goed op het ASTAP programma forum.
Han
January 28, 2020 at 17:54 #22954InFINNityDeckParticipantToch is het wel vreemd. Ik begrijp niet goed waarom de helft verworpen wordt. De x-array die je noemt in post 22929 bevat neem ik aan het verschillen tussen de theoretische hyperbool en de meetwaarden? Kan je mij je laatste Excel sheet sturen, dan kan ik er volgende week naar kijken, deze week lukt waarschijnlijk niet meer.
Nicolàs
https://www.dehilster.info/astronomy
In the observatory: Mount: 10Micron GM3000HPS, OTAs mounted: SW Esprit 80ED & Esprit 150ED, Celestron C11 XLT EdgeHD, Lunt LS80THA single stack, GTT60 (60mm aperture Galilean Type Telescope), Cameras: ZWO ASI1600MM Cool (2x), ASI174MM, ASI290MM & MC, QHYCCD QHY163M, OTAs on the ground: SW Explorer 300PDS, Bresser Messier 130/650 & 90/500.
January 28, 2020 at 19:40 #22955han.kParticipantHallo Nicolàs,
Ik wou je een berichtje sturen maar dus lukt niet in dit forum. ??? Je kan me mailen hier
Bijgevoegd alle data van vier focus testen:
– M39 (APO 100 mm)
– M39 met 50 perc obstruction (APO 100 mm)
– M107 met 50 perc obstruction (APO 100 mm)
– 12 inch newton
De hfd waarden gevonden staan ongeveer in row 40. Meestal gebruik if kolom hfd_cent. Dat zijn de hfd waarden van het centrum van de opname. De ASTAP hyperbool oplossing staat op G2. De invoer data is gekopieerd naar input op kolom A en B.
Het mediaan probleem staat in spreadsheet: “M39 with 50perc obstruction median error problem.xls” en in “problem mad.xls”
Als je een hyperbool kan vinden m.b.v. de data ben ik benieuwd wat je waarden zijn. De data van de 100mm APO is erg schoon. In een paar spreadsheets heb ik outliers toegevoegd zoals in de file naam staat.
De 50 percent obstruction was van een test voor hfd detectie. De APO voorkant was in het centrum met een stuk karton afgedekt om een Newton beeld te creëren, d.w.z. donut vormige sterren.
Han
Attachments:
You must be logged in to view attached files.January 28, 2020 at 20:18 #22958InFINNityDeckParticipantIk heb de data gedownload, je kan de bijlagen eventueel verwijderen.
Nicolàs
https://www.dehilster.info/astronomy
In the observatory: Mount: 10Micron GM3000HPS, OTAs mounted: SW Esprit 80ED & Esprit 150ED, Celestron C11 XLT EdgeHD, Lunt LS80THA single stack, GTT60 (60mm aperture Galilean Type Telescope), Cameras: ZWO ASI1600MM Cool (2x), ASI174MM, ASI290MM & MC, QHYCCD QHY163M, OTAs on the ground: SW Explorer 300PDS, Bresser Messier 130/650 & 90/500.
February 3, 2020 at 23:45 #22963InFINNityDeckParticipantHoi Han,
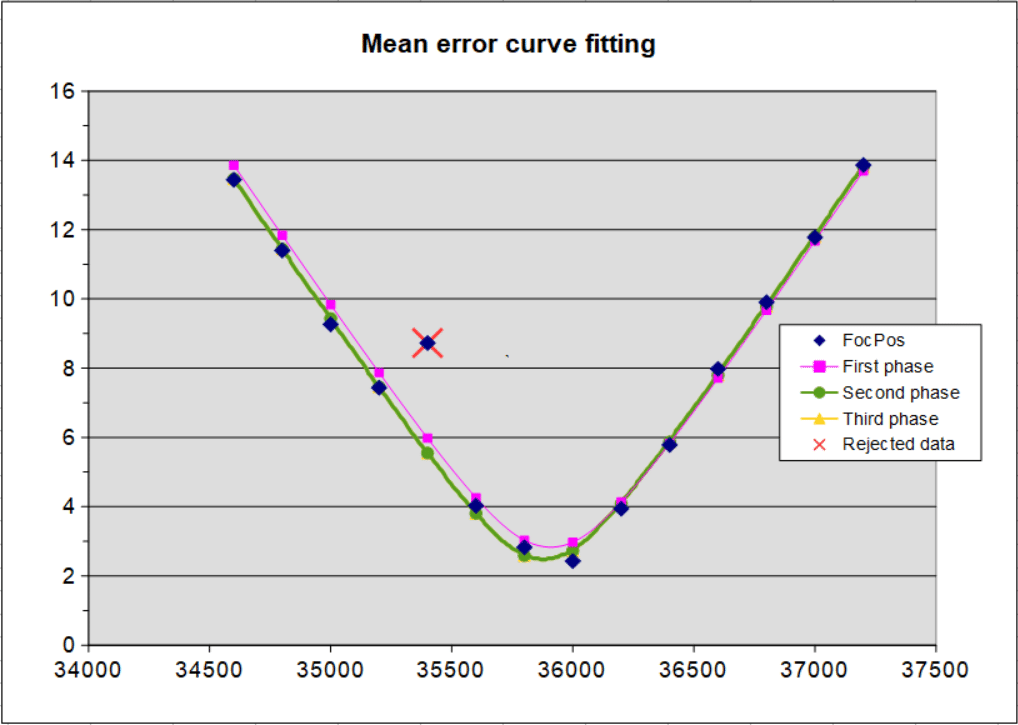
je moest even geduld hebben, maar hier is ie dan. Met behulp van MAD je data gefilterd en er was slechts één iteratie nodig om een stabiel resultaat te behalen (daardoor is de derde fase in de grafiek niet zichtbaar). In het Excel-sheet heb ik ruimte gemaakt voor twee iteraties, maar die tweede zal je niet vaak nodig hebben. Ik heb gefilterd op 3 kappa (98%), al zag ik dat het voor deze dataset ook meteen goed ging op 2 kappa (95%). Bij 1 kappa (68%) wordt meer data verworpen, maar sowieso zou ik 1 kappa niet snel gebruiken, dus blijf bij 2 of 3 kappa.
De best-fits heb ik met de solver van OpenOffice Calc gemaakt, daarbij gebruik makende van het niet lineaire DEPS Evolutionary Algorithm.
De eerste fase is dus een best-fit op de ruwe data.
De tweede fase is de best fit met de data die overbleef na filtering.
Daarna werd geen data meer verworpen, de derde fase is dus gelijk aan de tweede.Nicolàs
Attachments:
You must be logged in to view attached files.https://www.dehilster.info/astronomy
In the observatory: Mount: 10Micron GM3000HPS, OTAs mounted: SW Esprit 80ED & Esprit 150ED, Celestron C11 XLT EdgeHD, Lunt LS80THA single stack, GTT60 (60mm aperture Galilean Type Telescope), Cameras: ZWO ASI1600MM Cool (2x), ASI174MM, ASI290MM & MC, QHYCCD QHY163M, OTAs on the ground: SW Explorer 300PDS, Bresser Messier 130/650 & 90/500.
February 4, 2020 at 12:01 #22969han.kParticipantNicolàs,
Bedankt voor de aanpassingen. De spreadsheet heb ik geladen in Open Office. Helaas zijn de solver instellingen niet meegekomen. De solver krijg ik niet aan het werk. Zie onder. Zijn dit de goede instellingen?
Er blijft volgens mij een fundamenteel probleem dat de afwijkingenpopulatie niet aan een standaard normaal verdeling voldoet. De afwijkingen zijn dus niet volgens een Gaussische kromme verdeelt. Ik heb in principe de zelfde routines in Pascal programeertaal uitgeprobeert en bij een sigma ofwel standaard devatie (wat jij kappa noemt) van 2, of 2.5 of 3 dan wordt er altijd een outlier gevonden bij goede V-curve data. Deze ligt dan of 1) bij het focus (waar de de data van de hyperbool af kan wijken door de seeing) of 2) bij een van de wings omdat een van de wings een iets andere helling heeft. Deze goede data wordt pas weer meegenomen als ik de sigma (kappa), 5 of 7 maak. Maar dan werkt de statistiek totaal niet meer en worden er nooit outliers gevonden.
Dus met pratijk data zie ik dat er altijd minstens een outlier gevonden wordt ook bij een sigma(kappa) van 3. Je bent in dat geval dus goede data aan het weggooien. De hyperbool is een goede tot zeer goede benadering voor de focus V-curve maar de afwijkingen van de focus V-curve zijn niet normaal verdeelt. Mijn huidige strategie is nu de invloed van outlier(s) te beperken. De fout tussen V-curve en hyperbool wordt als volgt berekend (Pascal):
{smart error calculation to limits errors for extreme outliers} error:=hfd_hyperbola - v_curve[i,2] ;{hfd error in simulation} if error < 0 then total_error:=total_error - error/v_curve[i,2] {if v_curve[i,2] is large positive outlier then limit error to v_curve[i,2]/v_curve[i,2]=1 maximum} else total_error:=total_error + error/hfd_hyperbola; {if v_curve[i,2] is large negative outlier then limit error to hfd_hyperbola/hfd_hyperbola=1 maximum}Je kan statistiek wel toepassen als voor elke focuspunt drie of meer metingen worden gedaan. De afwijkingen van deze meetwaarden voldoen wel aan een normaal verdeling.
Nietemin, de spreadsheet wil ik verder uitproberen. Nu alleen nog de solver aan het werk krijgen.
Han
February 4, 2020 at 16:16 #22970InFINNityDeckParticipantHoi Han,
Om de solver aan de praat te krijgen, moet je deze extensie installeren.
Wat ik kappa noem is niet de standardafwijking, maar het aantal keer de standardafwijking, of beter gezegd, het aantal keer de geschatte waarde ervan op basis van de MAD. Bij kappa=1 is de kans dat het datapunt onterecht verworpen wordt 32%, bij kappa=2, is dit 5%, bij 3 is dit 2%. Als je mijn Excel-sheet bekijkt, dan zie je hoe ik dat doe.
Het testen doe je op de berekende fouten (de errors), aangezien deze (hopelijk) wel stochastisch verdeeld zijn. Je hebt dus geen meerdere runs nodig om meerdere punten per focusstand te krijgen. Het hele idee is, dat de hyperbool het model van je gemiddelde is en dat de afwijkingen als ruis daarom heen vallen. Wat je feitelijk doet is de outlier-detectie onafhankelijk maken van de focuspositie. Dat was precies de reden waarom ik liever niet een kwadratische fit zag in SGP, aangezien dat model slechts een grove benadering is van de werkelijkheid.
Ik heb een aantal proeven gedaan en geen rare resultaten gekregen, de methode is bij mij tot nog toe robuust gebleken. Als jij nog gevallen hebt waarbij het fout gaat, dan hoor ik dat graag.
Nicolàs
https://www.dehilster.info/astronomy
In the observatory: Mount: 10Micron GM3000HPS, OTAs mounted: SW Esprit 80ED & Esprit 150ED, Celestron C11 XLT EdgeHD, Lunt LS80THA single stack, GTT60 (60mm aperture Galilean Type Telescope), Cameras: ZWO ASI1600MM Cool (2x), ASI174MM, ASI290MM & MC, QHYCCD QHY163M, OTAs on the ground: SW Explorer 300PDS, Bresser Messier 130/650 & 90/500.
February 4, 2020 at 16:35 #22972InFINNityDeckParticipantHan,
hierbij nog het instellen van de OpenOffice Calc solver:
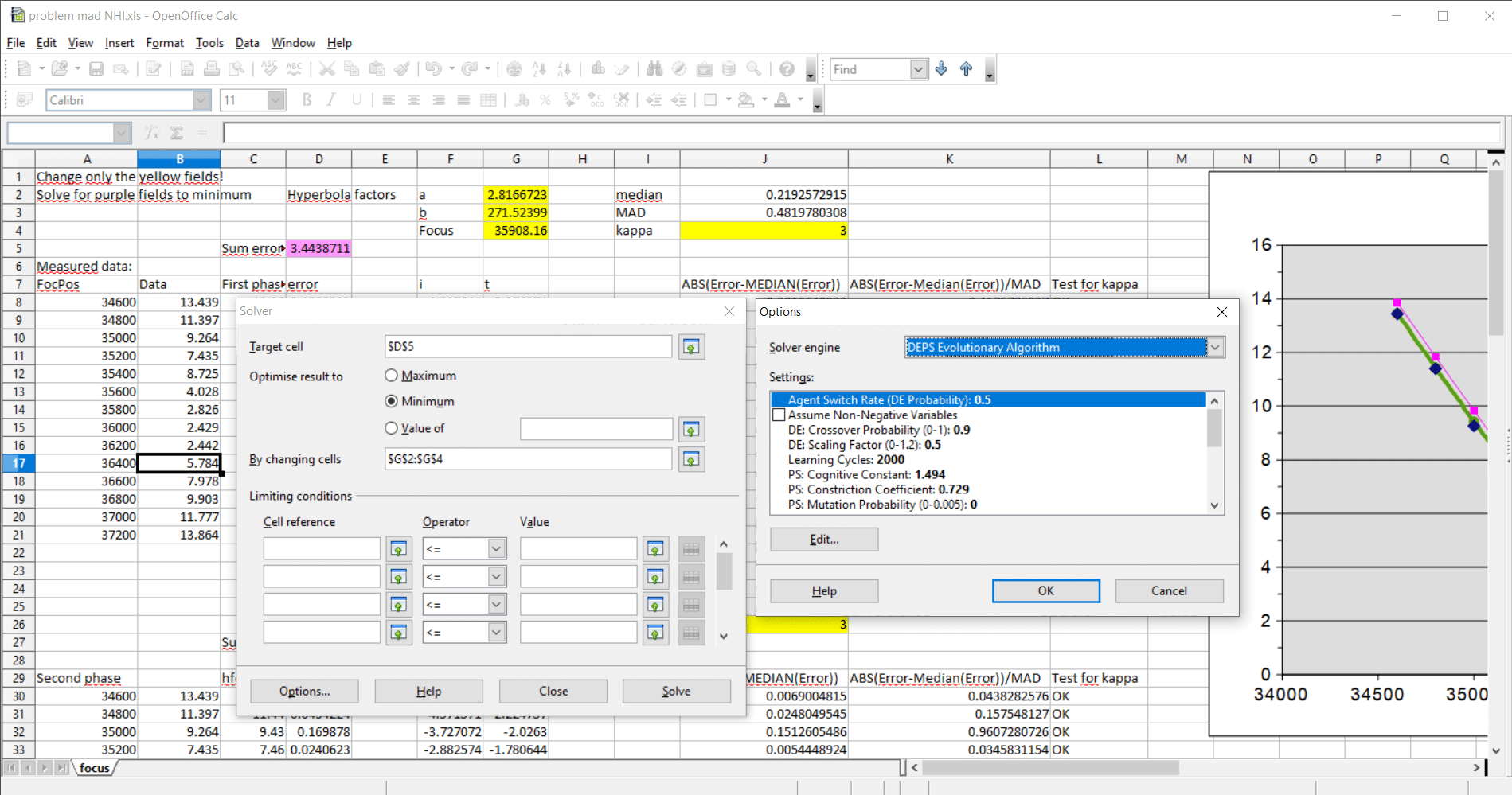
De target-cell is de magenta cell (D5) in het werkblad, die moet worden opgelost voor een minimum, “by changing cells” de drie gele cellen G2:G4. Vervolgens klik je op “Options” en selecteer je DEPS. Verder hoef je geen instellingen te maken, gewoon op OK klikken en vervolgens op solve. In de grafiek kan je dan vervolgens live meekijken wat de solver doet. Mijn laptop heeft circa 12 seconden nodig om een best fit te maken.
Vervolgens maakt het werkblad zelf de keuze welke waarden uitschieters zijn. Beneden de eerste fase vind je de tweede fase. Daar zet je de solver wederom aan het werk, nu door D27 naar een minimum te brengen door cellen G24:G26 te laten wijzigen door de solver. Eventueel kan je de kappa waarden aanpassen, ze staan momenteel op 3 (98% criterium).
Mocht er dan nog een punt verworpen worden, dan kan je daaronder de derde fase uitvoeren. D49 moet dan minimaal worden door G46:G48 te laten wijzigen.
Ik heb zojuist nog een test gedaan, waarbij ik het resultaat van focuspunt 36200 verlaagd heb met 1.5 (dus als waarde heb ik daar nu 2.442). In dat geval had ik de derde fase nodig om tot een stabiele oplossing te komen. Daarbij werden zowel 35400 als 36200 verworpen, de best focus werd gevonden bij 35881.4.
Nicolàs
https://www.dehilster.info/astronomy
In the observatory: Mount: 10Micron GM3000HPS, OTAs mounted: SW Esprit 80ED & Esprit 150ED, Celestron C11 XLT EdgeHD, Lunt LS80THA single stack, GTT60 (60mm aperture Galilean Type Telescope), Cameras: ZWO ASI1600MM Cool (2x), ASI174MM, ASI290MM & MC, QHYCCD QHY163M, OTAs on the ground: SW Explorer 300PDS, Bresser Messier 130/650 & 90/500.
February 4, 2020 at 22:12 #22973InFINNityDeckParticipantHoi Han,
ik heb nog even naar je stukje Pascal code gekeken. Je hoeft een negatieve error niet anders af te handelen dan een positieve. De correcte workflow voor het testen op outliers en vinden van de uiteindelijke focuspositie is als volgt:
1) Stel de kappa-waarde in (2 of 3) en maak een inschatting van parameters a, b en Focus
2) Bepaal het verschil tussen ieder datapunt en de op a, b en Focus gebaseerde hyperbool (dit zijn de errors)
3) Bepaal de wortel van de kwadratensom van deze errors
4) [START ITERATIELOOP] Bepaal de hyperbolische best fit op basis van het minimaliseren van de kwadratensom door a, b en Focus aan te passen en stappen 2) en 3) te herhalen, dit resulteert in nieuwe waarden voor a, b en Focus
5) Bepaal de mediaan van de errors: MEDIAN(Error)
6) Bepaal voor ieder datapunt ABS(Error-MEDIAN(Error))
7) Bepaal de MAD: 1.4826*MEDIAN([alle gevonden waarden in 6)])
8) Bepaal voor ieder datapunt ABS(Error-Median(Error))/MAD
9) Toets voor ieder datapunt of de uitkomst van 8) de kappa-waarde overschrijdt: indien dit het geval is dan vervalt het datapunt
10) Herhaal vanaf stap 4) totdat er geen verwerpingen meer plaatsvinden.
11) Presenteer de gevonden waarden voor a en Focus (de waarde van b is minder interessant voor de gebruiker).Nicolàs
https://www.dehilster.info/astronomy
In the observatory: Mount: 10Micron GM3000HPS, OTAs mounted: SW Esprit 80ED & Esprit 150ED, Celestron C11 XLT EdgeHD, Lunt LS80THA single stack, GTT60 (60mm aperture Galilean Type Telescope), Cameras: ZWO ASI1600MM Cool (2x), ASI174MM, ASI290MM & MC, QHYCCD QHY163M, OTAs on the ground: SW Explorer 300PDS, Bresser Messier 130/650 & 90/500.
February 4, 2020 at 22:47 #22975han.kParticipantHallo Nicolàs,
Ik ga morgen met je spreadsheet experimenteren.
>>>Je hoeft een negatieve error niet anders af te handelen dan een positieve
Dat doe ik om teveel invloed van grote outliers te voorkomen. Dit voorkomt grote percentuele afwijkingen daar de afwijking begrenst wordt tot 1. Zowel een HFD van 0 of 99 geeft een fout van 1 maximaal.
>> Bepaal de wortel van de kwadratensom van deze errors
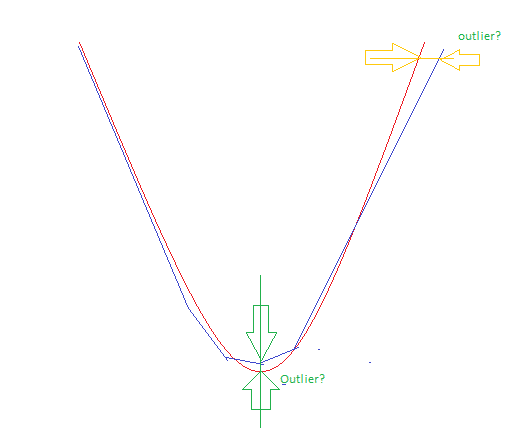
Deze manier van fout berkening heb ik inmiddels laten vallen. Het curve fits resultaat wordt beter met de gemiddelde absolute fout. De reden is dat de hyperbool niet altijd perfect past en de grootste afwijkingen teveel invloed krijgen door het kwadraat. Bijvoorbeeld als een van de hyperboolvleugels een andere hoek heeft. Daarnaast zijn outliers minder een probleem omdat de HFD waarde (FWHM) bepaald word als mediaan van aantal sterren HFD waardes in de opname. De mediaan filtert de slechte HFD detecties er uit. Dus aanvullende detecteren van outliers voor de curvefit heeft weinig prioriteit en ik heb de indruk dat het de curve fitting schaad.
Momenteel heb ik de indruk dat er altijd een outlier gevonden word. Deze zit of bij het focus door de seeing of bij een afwijkende hoek van een van de vleugels. Dat heb ik met onderstaande schets proberen weer te geven.
Vanavond heb tijdens een paar uur helder hemel al mijn focus opnames met een speciale versie van CCDCiel bewaard en kan ik meer analyseren.
Han
Attachments:
You must be logged in to view attached files.February 5, 2020 at 15:37 #22977han.kParticipantHallo Nicolàs,
The open-office curve fitting werkt nu met het DEPS evolutionary algorithm. De solver is wel bijzonder traag maar dat zal wel aan de grafiek liggen. Het maakt experimenteren moeizaam. In de spreadsheet zou ik de mediaan error vervangen door average error. Het is me onduidelijk hoe de kappa gelezen wordt door de solver. Na wat testen laat ik het nu even liggen.
De Nina ontwikkelaars gebruiken ook een solver van derden voor de V curve fitting. Dat lijkt me moeilijk om op langer termijn vol te onderhouden. Mijn voorkeur gaat uit naar eigen source code. De CCDciel & Astap solver is maar honderd regels code maximum. Daar heb ik geen library voor nodig.
Han
-
AuthorPosts
{kind=link}
- You must be logged in to reply to this topic.